
好,忙到一個小段落可以來寫個文章。Keyword Extraction 是個很大的主題,我也只能就我知道的方向討論,歡迎大家在下面留言跟我聊聊哈哈。
首先,所謂 Keyword Extraction 顧名思義我們想要從文章中找尋關鍵字。然而,關鍵字的概念其實是相對的。如果今天有兩篇文章,一篇是資工的學術文章,一篇是蘋果日報的八卦廢文。如果在完全沒有背景知識下,你大概只能就兩篇文章各自的重點來尋找關鍵字,然而你說說到底啥是重點啊????
對於沒有背景知識的人來說,所謂的重點和不是重點其實很難區分。通常最簡單的做法可能是,讓我們來看看類似的文章或是同個領域的文章,其他文章沒有但是這篇文章有,那可能就是重點了。你可能會覺得,這是什麼搞笑的做法,誰會這麼讀文章?就算是蘋果的八卦文章,重點可能是哪個小模,去了哪邊拍寫真集,或是在哪裡被拍到跟誰摟腰等等。你可能會試著了解文章的內容,建立文章的觀念系統,然後尋找真正重要的概念。
所以讓我們好好定義今天要討論的問題:對於一篇給定的文件,我們希望尋找到可以在語義上代表這個文件的關鍵字或關鍵詞。 (For a given written document, we try to find the words or phrases that best represent the semantic meaning of the original document.)
好了,直覺的方法很多,我廢話也講了不少,所以到底要怎麼找關鍵字?別急,Keyword Extraction 說到底仍然是個自然語言分析 (NLP) 的問題,我們先來看看在語言學上分析語言的層次,再來看看個別方法的長處。
從 NLP 來看 Keyword Extraction

圖片取自 Wikimedia Commons
這張由內而外表達了在語言學上對於語意分析的層次。畢竟我真的不是 NLP 的專家,有錯還請告訴我Orz。最裡面的聲韻學 Phonology & Phonetics 我們就不提了,畢竟文章的文字不會自己說話嘿嘿。
再來的 Morphology 討論的是英文每個字可能會有的標記,像是過去式 +ed,最高級 +est 等等的,讓我們對於每個字所表達的意思可以有所了解。 Syntax 討論的就會是字與字的組成,也就是文法,例如:一個句子 Sentance 會有名詞子句 Noun Phrase(NP) 及動詞子句 Verb Phrase(VP) 組成等等。到這裡,我們都還沒有提到任何關於語意的問題。
再來, Semantics 所研究的事就是由各個單字 words 或片語 phrases 所組成的語意。就目前 NLP 的研究發展,我們開始慢慢有系統的整理記錄還有預測文字所代表的意思。你可能會覺得 Siri 都知道我在嗆她了,這有什麼難的?這超難的!目前的系統很多都是 rule-based 靠超級多規則來判斷意思,沒辦法單純從文字的組成及單字的意思來了解。如果有興趣可以搜尋 Semantic Representation 或是我比較有接觸的 AMR 可以了解更多。
最後的 Pragmatics 是目前 NLP 完全還沒有能力碰到的領域。這研究的是語境下語言意義的改變,這在 NLP 上目前還沒有有系統的研究方法,或是可規模化的研究。當然拿 Twitter 資料預測反諷或是阿拉伯文在不同的場合所使用的文字及代表的意思都是目前很活躍的研究領域,這些都跟 Pragmatics 有關。
好了,再不說 Keyword Extraction 我就要被打了。
Keyword Extraction 的方法
好,來到方法。我自己認為可以將這些方法從概念上放到光譜上,左右分別是:Syntax-based 及 Semantic-based。我們可以在不了解文字意義下試圖尋找關鍵字,也可以從語意上出發,當然也有方法是介於兩者之間的。
再下來介紹的方法,都會介於 Syntax 和 Semantics 之間。這也是為什麼前面會先花點時間介紹這些層次的原因。
由於我想要介紹的方法大概介於個光譜的左右兩邊,所以我就乾脆拆成上下兩集來寫,希望下集不要難產(跪
這些方法的前提都是:你有很多資料可以拿來當作 training data。
Co-occurance Method
這類的方法時常有人會再區分出更基本的 Frequency-based Methods ,但是我覺得基本的概念其實是相同的。如果這些字詞只頻繁的出現在這篇文章中,那這些字詞大概就是關鍵字了。關於這種討論字詞出現頻率的的方法,就非 TF-iDF 莫屬了。由於我超級懶,不想要再認真寫他的內容,所以勒直接引用好友大維的文章。
然而,在這個狀況下,我們目的不是要比較兩個 document 相似的程度,而是想要找到特別的字詞或是廣義地稱為 tokens 。我們會盡量把我們認為有可能是關鍵字的字詞包裹成 token ,因此會用更多種類的 tokenizer 或是刪掉不太可能是關鍵字的字詞,例如 stop-word filter 。 我們不只可以用 Bag of Word ,也可以用 Bag of N-gram 或是用特殊的 Named Entity Tagger。
所謂的 word n-gram 就是無腦的移動框框來建立可能的片語。舉例而言
New York is one of the biggest city in the United States
所謂的 2-gram 就會是 New York, York is, is one, one of, of the, the biggest, biggest city, city in, in the, the United, United State 這麼多項。我們想要的片語包含在這些可能的片語當中,例如 New York, United States。我們可以透過 TF-iDF 來找出分數高的 2-gram,進而刪掉那些沒用的。
所謂 Named Entity 就是一些預先知道的專有名詞,通常是人名、國名、公司名等等。 Named Entity Tagger 有許多開源的工具可以使用。經典的算是 Stanford Named Entity Recognizer 還有 Illinois Named Entity Tagger 。 使用 python 的人也可以使用 NLP 的經典工具 Natural Language Toolkit(NLTK) ,裡面的也包含了 Stanford NER 的 python interface 。
特定的領域也可以用一些特定的專有名詞字典,可以大大增加找到關鍵字的機率。類似醫學領域可以使用 ULMS 來對應醫學專有名詞,附上我學長做的快速查詢工具。
這類方法可以詳見這篇 Brain Lott 的 Servey Paper 。
單純的使用 TF-iDF ,我們可以選取分數高的 token 當作我們要找的 keywords ,但是並沒有了解任何語意上的內容。稍微複雜一點的方法,我們可以進一步利用 Topic Modeling 來幫忙。
Topic Modeling
Topic Model 最有名的作法應該算是 Latent Dirichlet Allocation 。他的概念基本上是將 document 中的 token 根據 co-occurance 藉由 Singular Value Decomposition 來做 document clustering 。噴了這麼多專有名詞,你一定會說:這哪裡來的語意!!還不是在那邊用 co-occurance !!
別急XD,讓我解釋一下。就我對 Topic Modeling 的理解,這是一個試圖利用 co-occurance 或是字詞統計來了解語意的方法,是個介於 syntax-based 和 semantic-based 之間的方法。一個有名的語言學直覺:如果兩個字出現在類似的前後文中,他們會有大約相同的意思 (similar words would appear in similar context)。同樣的,反過來說基本上也是符合直覺,有著類似文字的文章,他們大概也會有類似的意思。
概念上我們可以這麼使用 Topic Modeling:我們可以在每個 topic group 和別人區別最大的 token 當作組內 document 的關鍵字。進一步,在每個組內再使用其他方法來尋找更細緻的關鍵字。
這樣的做法可以找到有階層 hierachial 的關鍵字。尤其在跨領域的文件中,要單純用出現頻率來尋找關鍵字會面對不同領域文件數量不同來干擾 document frequency 的問題,因為某個領域的文件比較多所以他的詞被誤認為不重要的字(inverted document frequency 比較低)。用這樣的方法可以使得這種干擾的狀況變得比較小。
圖片擷取自 Rhody, Lisa. “Topic modeling and figurative language.” Journal of Digital Humanities 2.1 (2012): 19-35.
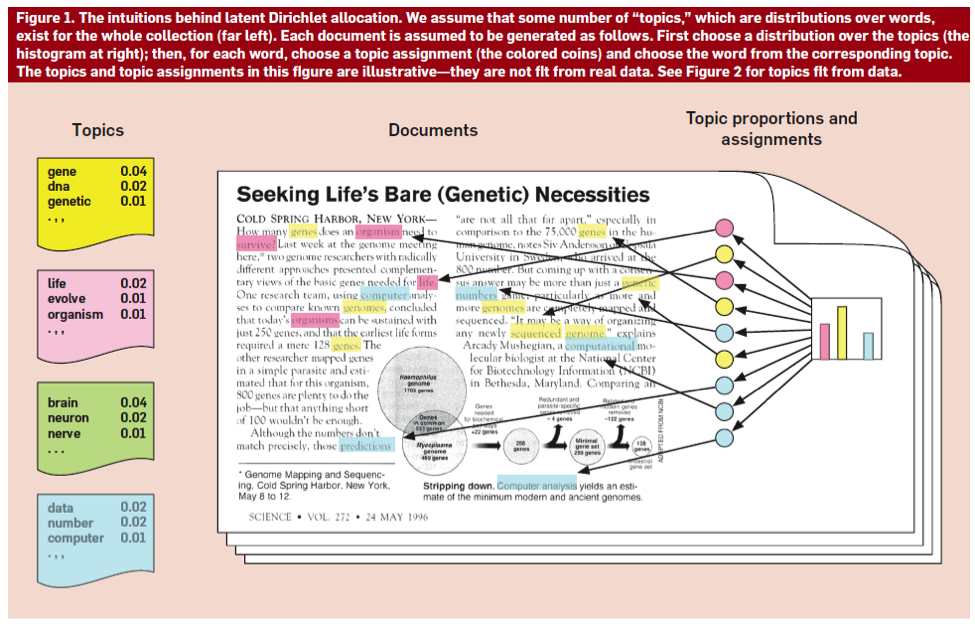
這張圖堪稱 Topic Modeling 最直覺也最好懂的圖了。右邊表達了各個 token 的詞頻和一起出現的機率,左邊的 Topic 就可以找出每個組內排行最高的幾個字,這就會是他們的關鍵字。而下面這張圖是 LDA 理論大概大家最愛引用的圖,這是來自於 Deep Learning, Computational Lingustic 大師 David Blei 的投影片。

圖片擷取自 David Blei 的投影片
LDA 是一個 inference algorithm,他試圖要估計隱藏的結構。這個模型的假設是這樣的,假設每個 topic 都是一個文字分佈( distribution over lexicons )、每個文件會由多個 topic 所生成的、而每個字則是最後可以觀測到的顯性變數。整個結構都是 latent variable 等著我們來 learn。
我們可以將每個結構都參數化並對參數做估計。估計的方法就不細講了,假設分佈在我們需要的點是否可微分會影響我們使用怎樣的估計方法。
Sloppy Conclusion
以上這些方法,大約就是常見的幾個透過 word co-occurance 衍生出來的方法了。
這些方法其實非常強大,他不需要透過外部的資訊來幫助我們尋找關鍵字,只要你有夠多的資料就可以有不錯的成果。當然,我覺得對於應用的方法應該永遠有個直覺:沒有一個方法可以完全打天下,在適當的時機要做適當的調整才能得到最好的結果。
以上的這些方法在你知道你正在處理什麼樣的資料的時候,都可以有些相對應的特化。別期待所有東西都可以用 out-of-the-box ,這些充其量只是作為生成 baseline 的工具。好好瞭解 domain knowledge 才是處理資料最重要的事情。





{kind=link}