
感覺這裡又再度長草,又到了除草的時間了。 最近聽了不少對機器學習或人工智慧非常概觀的演講,通常演講最後觀眾最喜歡提問的問題有兩個:
- 未來十年機器學習會發展到什麼程度?
- 人工智慧會取代人類的工作嗎?
第二個問題通常凸顯了人們對於人工智慧的過度緊張還有對於研究人員過於”美好”的期待。機器學習其實沒有想像中的厲害,尤其使用”學習”兩個字不知道讓多少人誤會了機器學習。
上週有人在 PTT 創世神在 DC 的一個非正式的活動中問了第二個問題,當時他用了一句話回答:
我們會因為家裡請了兩個保母就擔心媽媽沒有事情做了嗎?
我們總是會有新的問題值得人類來煩惱,但是我相信光是這樣是沒有辦法說服大家的。所以我想,白話的介紹一下人工智慧或是機器學習應該可以讓大家對於人工智慧或機器學習可以有比較”合理”的想像。
所以人工智慧在幹嘛
在人工智慧中,我們希望可以讓電腦做到人可以做到的事情。基本上這是個從功能或目標出發的做法 (Task-Oriented) 。我們試著讓他自己走路、自己看東西、自己尋找人、聽懂人說話、和人做些互動等等的。為了達成這些任務,以前我們硬寫很多規則讓電腦判斷,約莫就是一個口令一個動作的概念,有說過的他會做,稍微改了一點點他就不會了。
當然沒多久大家就發現這太蠢了,我們希望它有一定自己判斷的能力。但是判斷的依據是什麼?這就回到了老字號追求知識的手段了:演繹法和歸納法。在人工智慧(真的很不喜歡用這個詞Orz)中,我們有 Inference Engine 也有 Machine Learning ,這兩大類的方法基本上就是演繹及歸納。
Inference Engine 從整理好的規則或是邏輯式中進行自動推論 (Automated Reasoning) 。這些機器通常是藉由大量已經整理好的知識庫 (knowledge base) 來判斷某些事情是對是錯。我們常常也稱這些系統專家系統 (Expert System) 。
而 Machine Learning 就是耳熟能詳的髒話機器學習了。他透過大量已知的資料預測出我們想要的類別或是數值,這種目標我們稱為 Supervied Learning 。而試圖從資料中歸納出些什麼其他的東西,可能有用可能沒用的,這些稱為 Unsupervised Learning 。這兩個目標主要的差異在於我們有沒有想要預測的目標的正確答案。
當然這年頭有各種有趣的分支和有趣的方法,既然這篇文章的高度約莫10000英尺高,我們就先不多說這些了。
機器真的有在學習嗎
好,說了這麼多,機器真的有在學習嗎?我會說,機器在猜答案。真正學到東西的,目前看來還是我們這些人類。
人們試圖從資料中找尋可能對於結果有關的因素,我們越來越不關心是怎麼有關法,反正只要變成feature丟進去跑一跑大概就會有結果了。沒錯人們就是這麼隨便。
如果真的要認真討論,我們得先定義什麼是學習。知道某些資訊等於學習嗎?我們對於學習的定義真的有這麼膚淺嗎?攻防這個定義我想對於一篇部落格文章來說沒有什麼意義,但是至少這種猜答案式的機器,距離威脅人類的地位我想還有很長一段路。
即使現在機器學習有了長足的進步,機器圖片的處理和分類已經近乎完美了、對於產品銷售的預測也準到讓人吃驚。機器學習仍然有很多我們目前無法讓模型”理解”的東西。
因為怕被砲慘 ,我還是挑我自己的研究領域來說比較安全XD。目前在文字探勘或是NLP的領域,要讓模型了解兩個句子的關係其實還是很困難,不管是代名詞指稱的對象或是字詞在不同語境下代表什麼意思,其實都還是很困難的。這是 Nathan Schneider 在星期五的 group meeting 開的笑話:
Human: You really need to understand me more.
Siri: I will make a note of that.
Human: Yeah, you really need make of note of that.
Siri: Got it.
(A note with “Of that” on it)
這凸顯了機器要真的了解我們在說什麼還有很長一段路。更別說各種反串文或是諷刺文了,這些都是很多學長花了一輩子都還在研究的議題。
所以我們應該害怕什麼
很多非人工智慧或是機器學習領域的人對於人工智慧都有很多危機式的警語。 Steven Hawking 也曾公開的認為人工智慧對於人類是一種威脅。機器學習確實有值得我們擔心的地方,但是我想距離反撲人類啊毀滅人類啊都還滿有距離的。
-
當我們過度依賴資料來學習模型時,模型會高度受到資料而影響。如果有人刻意餵給他錯誤的資料
(就像親愛的白宮主人發的 Twitter 一樣)那我們的模型就會有被操弄的空間,進而對於社會或是人們造成影響。就像我們最剛開始都覺得電腦只是打打字看看東西,有什麼好擔心安全的。但是時至今日,資訊安全已經是所有人都應該注意的問題。機器學習上的安全問題也慢慢開始受到重視, Adversarial Machine Learning 就是在處理這樣問題的領域。
但是就算我們不是刻意操弄模型,很多模型也已經隱含了我們不願意看到的現象。如果我們去搜尋 professor ,前15張只有3張女性,大部分都是中年以上的男子(我真的不知道川普大大為什麼會在那裏….)。這直接反映了我們對於教授的想像:男性,中年,八成有禿頭。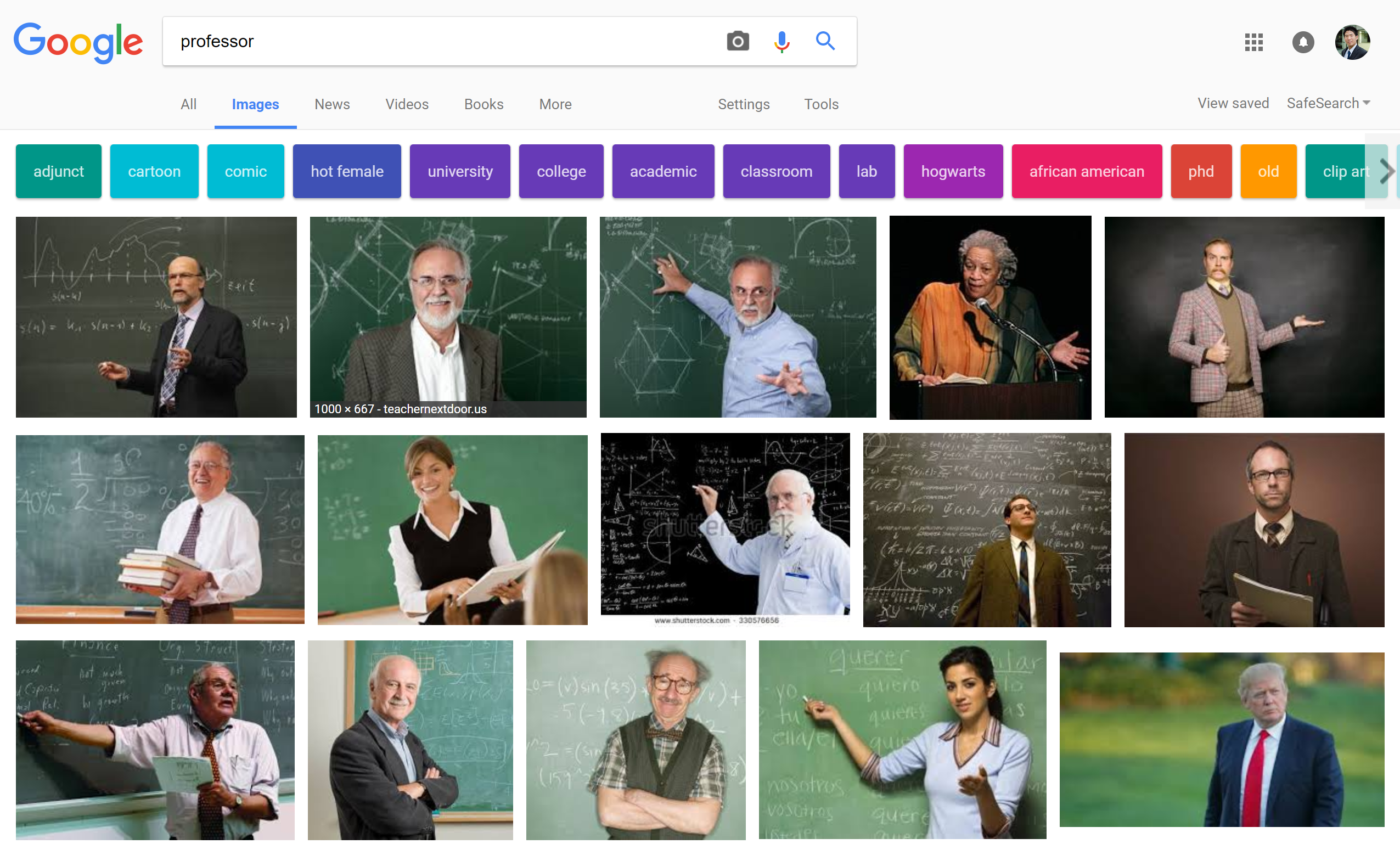 另一個有名例子是芝加哥警力分配根據犯罪率進行重分配。但是警方手上所握有的犯罪率資料其實只是”警方知道的犯罪”,警力越多帳面上的犯罪數量就容易越多,最後使得警力過度不偏重在特定區域。(說聲抱歉我找不太到原始文章,如果有人還存著可以傳給我讓我補上來,但是網路上已經有不少文章在討論 Predictive Policing 的問題了)
另一個有名例子是芝加哥警力分配根據犯罪率進行重分配。但是警方手上所握有的犯罪率資料其實只是”警方知道的犯罪”,警力越多帳面上的犯罪數量就容易越多,最後使得警力過度不偏重在特定區域。(說聲抱歉我找不太到原始文章,如果有人還存著可以傳給我讓我補上來,但是網路上已經有不少文章在討論 Predictive Policing 的問題了)
但是這該叫做 經驗 還是 偏見 ,這是個值得被討論的問題。或是我們應該問更基礎的問題:我們的經驗是不是都是種偏見? -
當我們開始讓模型從提供資訊的角度變成作 決策的角色,他是基於什麼標準而做出來的決策會成為很大的道德問題。機器學習有一個很大的應用就是在於 Decision Support。但是當模型本身直接開始做決策,判斷你能不能貸款、能不能申辦信用卡也許道德問題都還不嚴重。如果,機器開始判斷病人該不該被救、誰是不是犯人、他等等會不會去犯罪呢?是不是開始違背人性了? 過去有名的電車問題,也出現在自動駕駛車上。當今天選擇要撞死誰的時候,機器的選擇符合人性嗎?到底應該設計死最少人還是讓駕駛或是公司付最少賠償金?
(可能撞死黃種人最安全吧)
我們應該要記得:模型的結果永遠是個機率。 雖然真實世界中也充滿著機率,但是我們對於機率、對於風險我們會試著控管。這些數字對我們來說不會是冷冰冰的機率,背後可能代表飛機上旅客的安全、手術台上病人的性命、勝訴或敗訴的賠償金。機器只會告訴你他多會猜答案,但是不管多會猜,背後的風險仍然是我們在管理的。
每個事件、每個決策的當下,都隱藏著決策者的價值排序。在損益比較過程中,機器沒有辦法理解天秤上所有法碼背後所代表的意義。犧牲一條人命不等於賠償金,還代表背後的家庭,代表決策者信譽,代表責任。在機器沒有辦法了解人性之前,我相信永遠都沒有辦法,決策仍然是屬於人類而不是機器的。




